Trong quá trình phân tích, khi các thước đo biểu diễn vị trí/xu thế “trung tâm” (mean, median, mode) của 2 tập dữ liệu có giá trị xấp xỉ bằng nhau, ta sẽ gặp khó khăn khi cần đưa ra nhận xét, đánh giá sự khác biệt của 2 tập dữ liệu. Lúc này, các đại lượng đo mức độ phân tán của dữ liệu sẽ có ích hơn trong việc đánh giá.
Trong bài viết này, 6 đại lượng đo mức độ phân tán của tập dữ liệu sẽ được giới thiệu:
- Bách phân vị (Percentile)
- Tứ phân vị (Quartile)
- Khoảng biến thiên (Range)
- Khoảng trải giữa (InterQuartile Range)
- Phương sai (Variance)
- Độ lệch chuẩn (Standard deviation)
Các đại lượng này sẽ giúp ích trong việc đo lường mức độ biến thiên, mức độ phân tán và dàn trải của dữ liệu. Qua đó, có thể rút ra các nhận xét, mô tả bộ dữ liệu nghiên cứu đầy đủ và chính xác hơn.
1. Khoảng biến thiên (Range)
Khoảng biến thiên (Range) trong thống kê là đại lượng đo mức độ trải dài của một tập dữ liệu nhất định từ nhỏ nhất đến lớn nhất. Dễ hiểu hơn, trong một tập dữ liệu, khoảng biến thiên là hiệu số giữa giá trị lớn nhất và giá trị nhỏ nhất.
Công thức tính khoảng biến thiên:

Trong đó: R là khoảng biến thiên, xmax là giá trị lớn nhất, xmin là giá trị nhỏ nhất
Ví dụ: Cho tập dữ liệu X={2,4,5,6,7,8,9,12,15}.
Ta thấy giá trị lớn nhất của tập X là xmax=15 và giá trị nhỏ nhất là xmin=2 =>Khoảng biến thiên R là:

Trong thực tế, ta có thể thấy khoảng biến thiên được sử dụng trong rất nhiều tình huống, chẳng hạn như tìm ra sự phân tán điểm kiểm tra trong một lớp học hay để xác định phạm vi giá cả của một dịch vụ, …
Trong các đại lượng đo mức độ phân tán của dữ liệu, khoảng biến thiên là một đại lượng rất dễ hiểu và dễ tính toán. Tuy nhiên, khoảng biến thiên chỉ sử dụng giá trị MAX và MIN của tập dữ liệu để tính toán mà không diễn giải được sự phân tán giữa 2 giá trị này. Do đó, nó không phải là một đại lượng hữu ích để đánh giá sự phân tán của tập dữ liệu vì ta cần xem xét trên toàn bộ dữ liệu.
Khoảng biến thiên là thang đo tương đối tốt đối với các bộ dữ liệu nhỏ như ví dụ trên, nhưng độ tin cậy sẽ ít đi khi áp dụng với các bộ dữ liệu lớn do độ dàn trải của dữ liệu cũng sẽ lớn hơn. Một điểm cần lưu ý khác là giá trị của khoảng biến thiên sẽ bị ảnh hưởng bởi các giá trị ngoại lệ (Outliers)[1]. Do đó, không nên sử dụng đại lượng khoảng biến thiên đối với các bộ dữ liệu có giá trị ngoại lệ.
2. Bách phân vị (Percentile) và Tứ phân vị (Quartile)
Bách phân vị (Percentile) Tứ phân vị (Quartile)
ĐỊNH NGHĨA
Bách phân vị (Percentile) là đại lượng dùng để ước tính tỷ lệ dữ liệu trong một tập số liệu rơi vào vùng cao hơn hoặc thấp hơn so với một giá trị cho trước. Bách phân vị chia dữ liệu có thứ tự theo hàng trăm.
Có thể diễn giải qua ví dụ sau:
Ta có phân vị thứ p∈[0;100] và giá trị vp tại vị trí p thì:
- có ít nhất p% các quan sát có giá trị ≤vp
- có ít nhất (100-p)% các quan sát có giá trị ≥vp
Cụ thể qua số liệu:
Chẳng hạn tại phân vị thứ 85 của tập dữ liệu X có giá trị là 20 thì sẽ có nhiều nhất 85% số quan sát có giá trị thấp hơn 20 và có nhiều nhất (100-85)=15% số quan sát có giá trị lớn hơn 20.
Tứ phân vị (Quartile) là một trường hợp đặc biệt của bách phân vị. Tứ phân vị có 3 giá trị, đó là tứ phân vị thứ nhất, thứ nhì, và thứ ba. Ba giá trị này chia một tập hợp dữ liệu đã sắp xếp theo thứ tự thành 4 phần có số lượng quan sát đều nhau.
CÁCH XÁC ĐỊNH
Để xác định giá trị (vp) của phân vị thứ p trong một tập dữ liệu, ta thực hiện theo các bước sau:
1. Sắp xếp dữ liệu theo thứ tự từ nhỏ nhất đến lớn nhất.
2. Tính chỉ số i:

Trong đó:i là vị trí của giá trị dữ liệu tại phân vị thứ pp là phân vị thứ pn là tổng số quan sát
3. Xác định giá trị vp
– Nếu i LÀ số nguyên thì phân vị thứ p là giá trị dữ liệu ở vị trí thứ i trong tập dữ liệu.
– Nếu i KHÔNG phải là số nguyên thì làm tròn i lên và làm tròn i xuống số nguyên gần nhất, sau đó tính trung bình hai giá trị dữ liệu ở hai vị trí này trong tập dữ liệu.
– Giá trị tứ phân vị thứ nhất Q1 bằng trung vị phần dưới, tương đương với bách phân vị thứ 25.
– Giá trị tứ phân vị thứ hai Q2 chính bằng giá trị trung vị, tương đương với bách phân vị thứ 50.
– Giá trị tứ phân vị thứ ba Q3 bằng trung vị phần trên, tương đương với bách phân vị thứ 75.
VÍ DỤ
Một tập dữ liệu bao gồm 29 độ tuổi dành cho nam diễn viên xuất sắc nhất đoạt Giải Oscar theo thứ tự từ nhỏ nhất đến lớn nhất được cho như sau: X={18; 21; 22; 25; 26; 27; 29; 30; 31; 33; 36; 37; 41; 42; 47; 52; 55; 57; 58; 62; 64; 67; 69; 71; 72; 73; 74; 76; 77}Tìm phân vị thứ 70 và 83?
– Ta có: n = 29, p1=70, p2=83

– Vì i1=21 là số nguyên nên ta sẽ sử dụng giá trị dữ liệu ở vị trí thứ 21 trong tập dữ liệu là 64.
=> Phân vị thứ 70 là 64. Có thể kết luận 70% nam diễn viên xuất sắc nhất đạt giải Oscar có độ tuổi thấp hơn 64 và 30% nam diễn viên xuất sắc nhất đạt giải Oscar trên 64 tuổi.
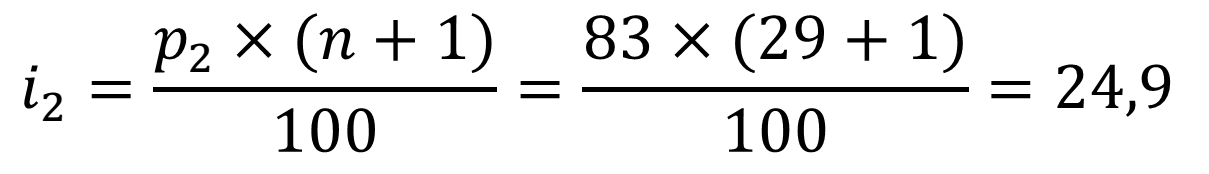
– Vì i2=24,9 không phải là số nguyên nên ta sẽ làm tròn xuống 24 và làm tròn lên 25. Tuổi ở vị trí thứ 24 là 71 và tuổi ở vị trí thứ 25 là 72. Trung bình cộng 71 và 72 là 71,5.
=>Phân vị thứ 83 là 71,5 tuổi.
Một tập dữ liệu được cho như sau:X={1; 11,5; 6; 7,2; 4; 8; 9; 10; 6,8; 8,3; 2; 2; 10; 1}Xác định giá trị Q1, Q2 và Q3?.
– Đầu tiên, sắp xếp lại tập X theo thứ tự tăng dần: X={1; 1; 2; 2; 4; 6; 6,8; 7,2; 8; 8,3; 9; 10; 10; 11,5}
– Tập dữ liệu có 14 quan sát, giá trị trung vị nằm giữa giá trị thứ 7 (6,8) và giá trị thứ 8 (7,2). Giá trị trung vị là trung bình cộng của 2 giá trị này:
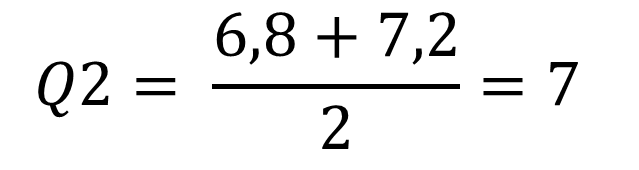
Q1, là giá trị giữa của nửa dưới dữ liệu tương ứng với tập dữ liệu X1={1; 1; 2; 2; 4; 6; 6,8}. Tập X1 có 7 giá trị, do đó giá trị trung vị của tập dữ liệu X1 là 2. => Q1 = 2
Q3, là giá trị nửa trên của dữ liệu tương ứng với tập dữ liệu X2={7,2; 8; 8,3; 9; 10; 10; 11,5}. Tập X2 có 7 giá trị, do đó giá trị trung vị của tập dữ liệu X2 là 9. => Q3 = 9
Kết luận: ¼ tập dữ liệu có giá trị ≤2, ¾ tập dữ liệu có giá trị ≥2. Tương tự kết luận với Q2 và Q3.
ỨNG DỤNG
Bách phân vị được sử dụng trong nhiều lĩnh vực như: đo lường băng thông internet, thước đo sự phát triển của trẻ em trong y học, đo lường mốc giới hạn tốc độ, báo cáo điểm số tổng quan trong các bài kiểm tra hay trong các lĩnh vực tài chính, v.v…
Ví dụ trong y học: Một trẻ nam 2 tuổi có chiều cao 110cm và cân nặng 13,3kg; khi so sánh với biểu đồ bách phân vị cân nặng và chiều cao theo độ tuổi của WHO thì chiều cao ở mức bách phân vị 50 và cân nặng ở mức bách phân vị 85.=> Kết luận: Đứa trẻ này cao hơn so với 50 trẻ và nặng hơn so với 85 trẻ khác trong 100 trẻ cùng lứa tuổi và giới tính.
Ngoài những ứng dụng tương tự như bách phân vị, tứ phân vị còn có công dụng kiểm soát tác động của những giá trị ngoại lệ (Outliers) ở 2 đầu mút. Để hiểu rõ hơn, ta sẽ tiếp tục tìm hiểu trong đại lượng tiếp theo: Khoảng trải giữa (InterQuartile Range)
3. Khoảng trải giữa (InterQuartile Range)
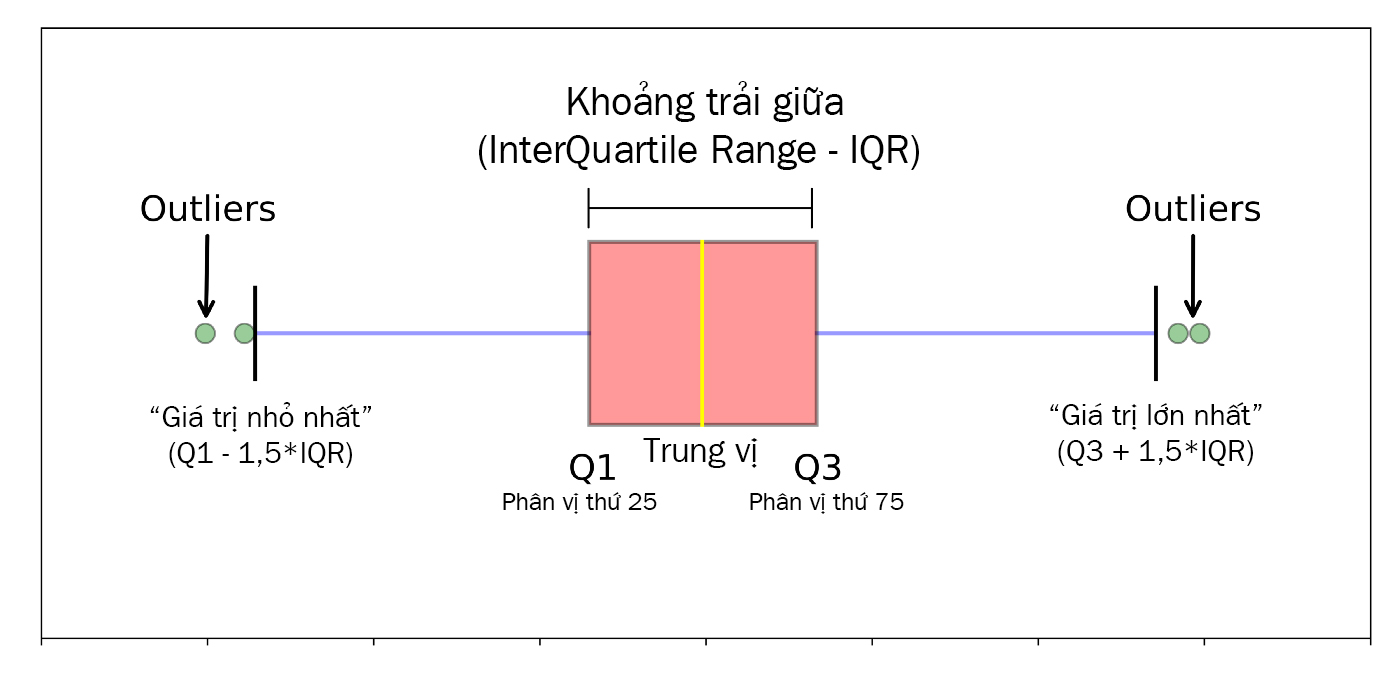
Khoảng trải giữa (InterQuartile Range – IQR) hay còn gọi là khoảng tứ phân vị của tập dữ liệu. Khoảng trải giữa là một con số cho biết mức độ lan truyền của nửa giữa hoặc 50% phần giữa của tập dữ liệu. IQR thường được sử dụng thay cho khoảng biến thiên (Range) vì nó loại trừ hầu hết giá trị bất thường hay giá trị ngoại lệ (Outliers) của dữ liệu.
Công thức tính IQR có dạng:

IQR có thể giúp xác định các giá trị ngoại lệ. Một giá trị bị nghi ngờ là một giá trị ngoại lệ nếu nó nhỏ hơn 1,5*IQR dưới phần tư đầu tiên (Q1 – 1,5*IQR) hoặc lớn hơn (1,5*IQR) trên phần tư thứ ba (Q3 + 1,5*IQR) (Xem hình dưới). Các giá trị ngoại lệ luôn yêu cầu việc rà soát, kiểm tra lại dữ liệu. Những điểm dữ liệu đặc biệt này có thể do lỗi hoặc do sự bất thường trong dữ liệu nhưng cũng có thể là chìa khóa để hiểu dữ liệu.
4. Phương sai (Variance) và Độ lệch chuẩn (Standard deviation)
Trong một số tập dữ liệu, các giá trị dữ liệu được tập trung gần giá trị trung bình; nhưng trong các tập dữ liệu khác, các giá trị dữ liệu có thể được trải rộng hơn so với giá trị trung bình. Phương sai và độ lệch chuẩn là 2 thuật ngữ được sử dụng phổ biến để mô tả sự phân tán này và cả 2 đều đưa ra các giá trị đo lường mức độ phân tán của dữ liệu xung quanh giá trị trung bình.
Phương sai (Variance) Độ lệch chuẩn (Standard deviation)
ĐỊNH NGHĨA
Phương sai (Variance) là thước đo độ biến thiên của các giá trị xung quanh giá trị trung bình số học của chúng, nó cho biết các giá trị đó ở cách giá trị kỳ vọng bao xa. Một cách dễ hiểu hơn, phương sai sẽ cho biết mức độ chênh lệch trong tập dữ liệu.
Phương sai thường được ký hiệu theo tính chất của tập dữ liệu:
– Đối với dữ liệu là một tổng thể: phương sai ký hiệu là σ2
– Đối với dữ liệu là mẫu từ tổng thể: phương sai ký hiệu là s2
Độ lệch chuẩn (Standard deviation) là thước đo độ phân tán của các giá trị trong một tập dữ liệu đã cho từ giá trị trung bình của chúng. Nó cho biết trung bình mỗi giá trị nằm bao xa so với giá trị trung bình.
Tương tự, độ lệch chuẩn cũng được ký hiệu:
– Đối với dữ liệu là một tổng thể: phương sai ký hiệu là σ
– Đối với dữ liệu là mẫu từ tổng thể: phương sai ký hiệu là s
CÔNG THỨC TÍNH
Phương sai là giá trị trung bình của bình phương khoảng cách của mỗi điểm dữ liệu tới điểm trung bình.
– Đối với dữ liệu là một tổng thể:
Công thức tính:
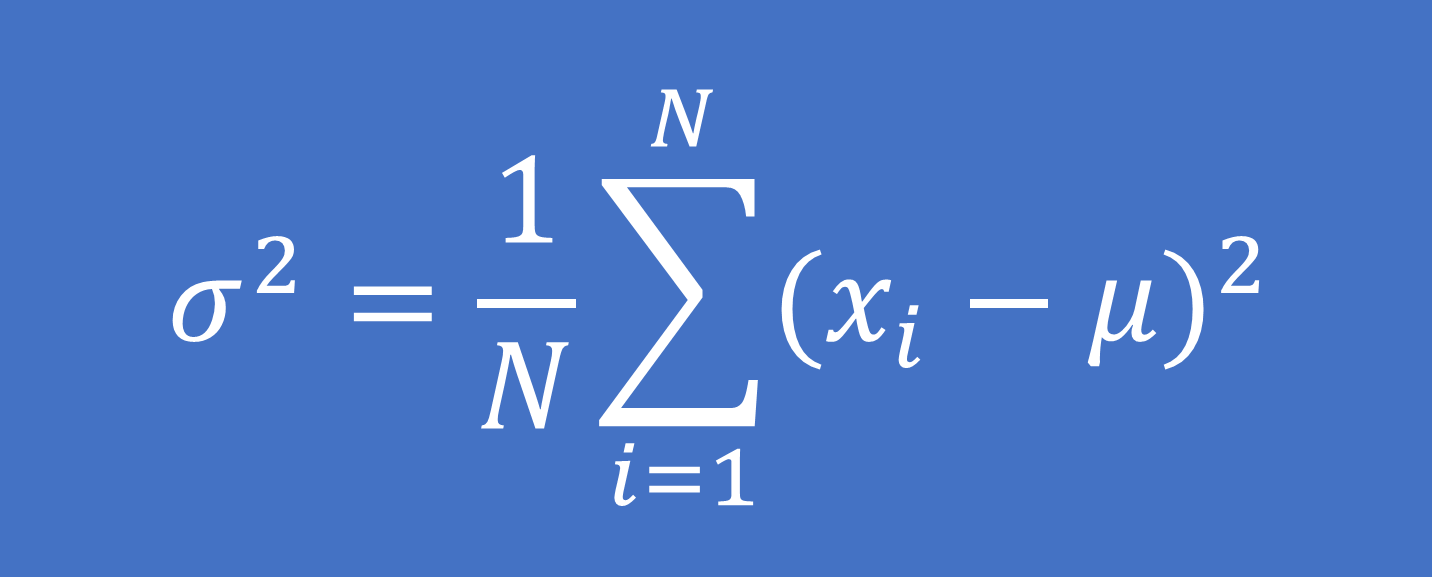
Trong đó: xi là giá trị của quan sát thứ i
μ là giá trị trung bình tổng thể
N là tổng số quan sát của tổng thể
– Đối với dữ liệu là một mẫu từ tổng thể:
Công thức tính:
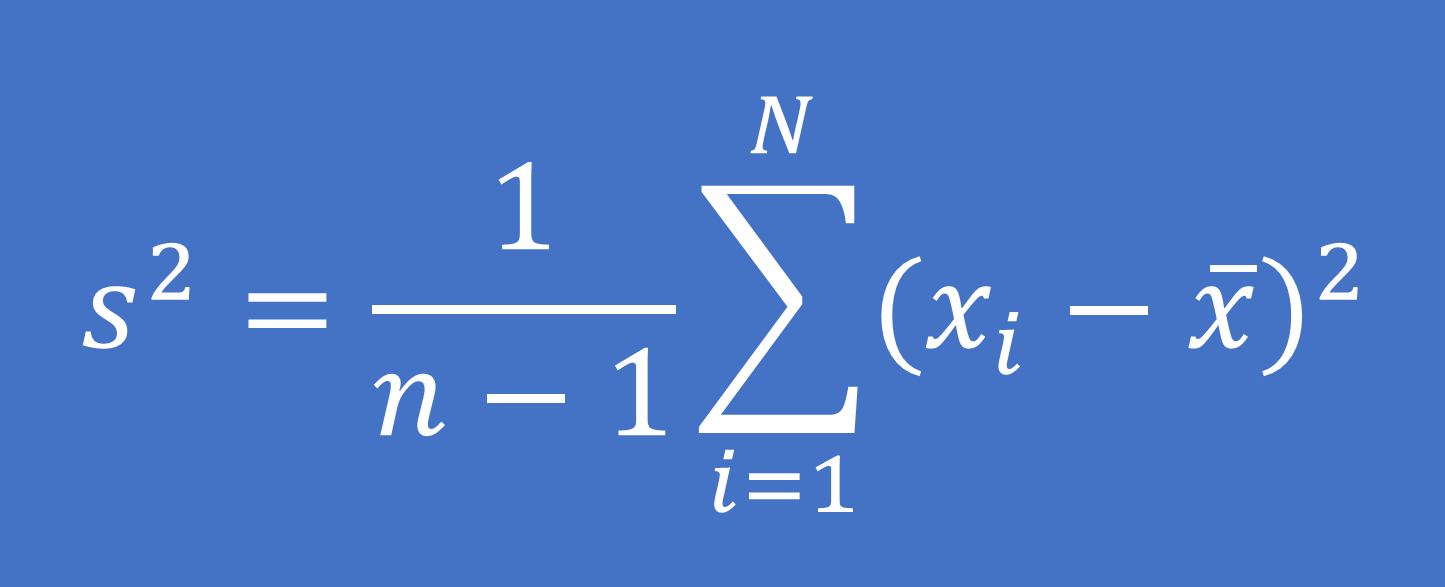
Trong đó: xi là giá trị của quan sát thứ i
x ̅ là giá trị trung bình của mẫu dữ liệu
n là số quan sát trong mẫu dữ liệu
Độ lệch chuẩn là căn bậc hai của phương sai.
– Đối với dữ liệu là một tổng thể:
Công thức tính:
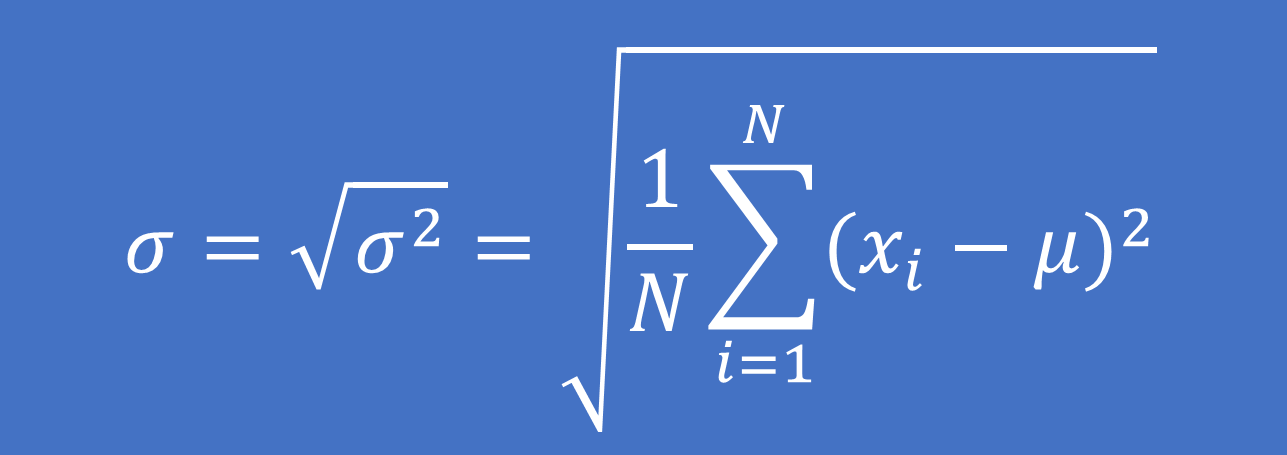
Trong đó: xi là giá trị của quan sát thứ i
μ là giá trị trung bình tổng thể
N là tổng số quan sát của tổng thể
– Đối với dữ liệu là một mẫu từ tổng thể:
Công thức tính:
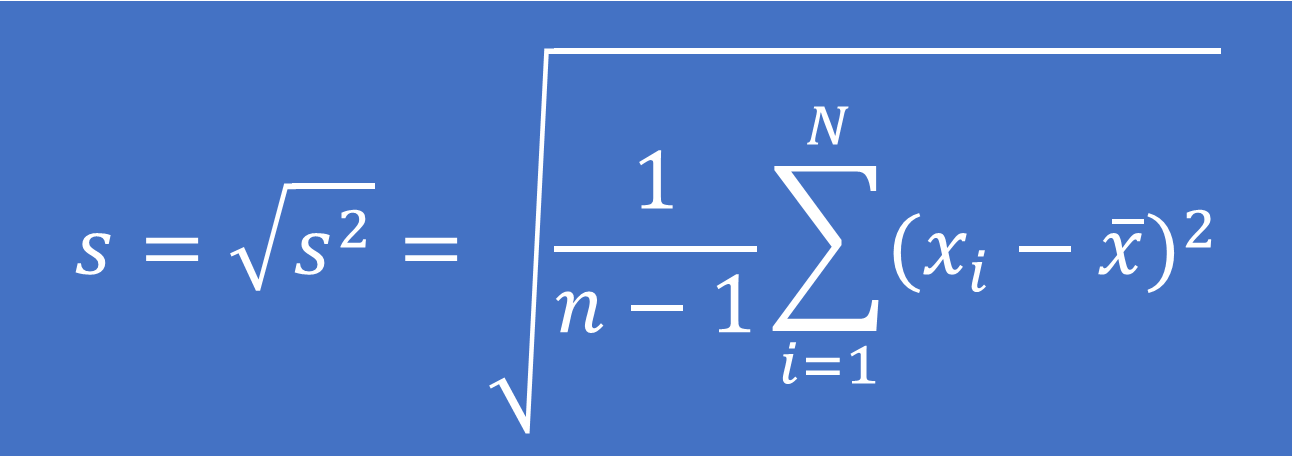
Trong đó: xi là giá trị của quan sát thứ i
x ̅ là giá trị trung bình của mẫu dữ liệu
n là số quan sát trong mẫu dữ liệu
VÍ DỤ
Mẫu dữ liệu về thời gian (giây) chạy cự ly 500m và 1500m của một nhóm gồm 5 người:T500 = {55.2, 58.8, 62.4, 54, 59.4}T1500 = {271.2, 261, 276, 282, 270}Tính phương sai chạy 2 cự ly 500m và 1500m.
– Tính giá trị trung bình của 2 mẫu dữ liệu:
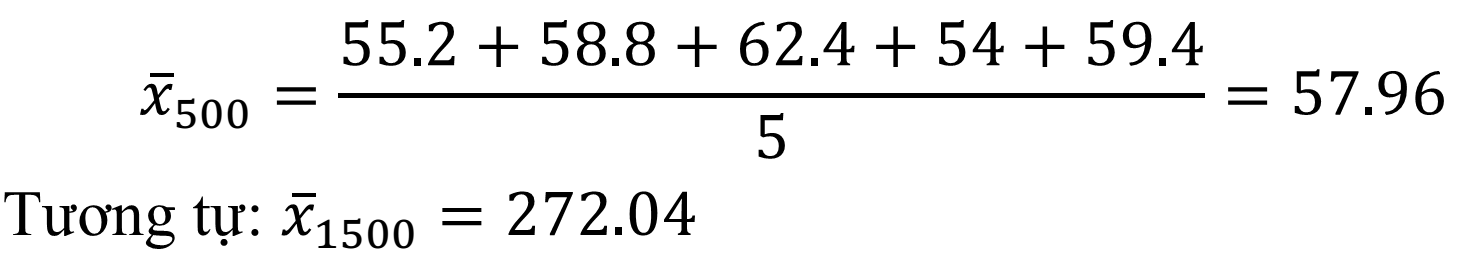
– Phương sai:

=> Kết luận: Phương sai của cự ly 1500m có giá trị cao hơn cự ly 500m, cho thấy có sự biến động mạnh hơn, tức dữ liệu có sự dàn trải rộng hơn giữa thời gian chạy của 5 người này..
Mẫu dữ liệu về thời gian (giây) chạy cự ly 500m và 1500m của một nhóm gồm 5 người:T500 = {55.2, 58.8, 62.4, 54, 59.4}T1500 = {271.2, 261, 276, 282, 270}Tính phương sai chạy 2 cự ly 500m và 1500m.
– Tính giá trị trung bình của 2 mẫu dữ liệu:
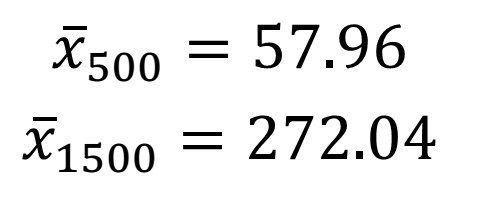
– Độ lệch chuẩn:
s500=3.38
s1500=7.77
=> Kết luận: Độ lệch chuẩn của cự ly 500m cho biết thời gian chạy 500m của 5 người này chỉ lệch trung bình 3.38s so với thời gian chạy trung bình 500m là 57.96s. Nhưng độ lệch chuẩn của cự ly 1500m đến 7.77s cho thấy với cự ly dài hơn thì thành tích trung bình của 5 vận động viên sẽ có sự khác biệt đáng kể hơn so với cự ly 500m.
ỨNG DỤNG
Phương sai được sử dụng trong các lĩnh vực như: trong công nghiệp, phương sai biểu thị độ chính xác của sản xuất; trong chăn nuôi, nó biểu thị độ đồng đều của các con gia súc; trong trồng trọt, nó biểu thị mức độ ổn định của năng suất; trong tài chính, nó là một tham số quan trọng trong phân bổ tài sản đầu tư, giúp các nhà đầu tư phát triển danh mục đầu tư tốt hơn bằng cách tối ưu hóa sự đánh đổi giữa rủi ro và lợi nhuận với mỗi khoản đầu tư, …
Bởi vì dễ hình dung và dễ áp dụng hơn nên độ lệch chuẩn thường được sử dụng như một thước đo chính của sự thay đổi của các dữ liệu trong tập dữ liệu.
Độ lệch chuẩn được sử dụng cho một số lĩnh vực như kiểm soát chất lượng sản phẩm, dự báo thời tiết, đo lường rủi ro biến động trên thị trường tài chính.
Ngoài ra, độ lệch chuẩn cũng có công dụng giúp chuẩn hóa giá trị của các dãy số khác nhau về cùng 1 miền dữ liệu.
LƯU Ý
Phương sai lớn cho thấy có nhiều sự biến động trong các giá trị của tập dữ liệu và có thể có khoảng cách lớn hơn giữa giá trị các quan sát với nhau. Nếu tất cả các quan sát đứng gần nhau, phương sai sẽ nhỏ. Tuy nhiên, việc giải thích giá trị phương sai một cách trực quan sẽ khó hiểu hơn nhiều so với độ lệch chuẩn.
Hạn chế lớn nhất của việc sử dụng độ lệch chuẩn là nó có thể bị ảnh hưởng bởi các giá trị ngoại lệ và các giá trị âm.
Duy Sang tổng hợp
Chú thích:[1] Dữ liệu ngoại lệ (Outliers) là một điểm dữ liệu có sự khác biệt đáng kể so với các quan sát khác. Dữ liệu ngoại lệ có thể xuất hiện do sự thay đổi thang đo hoặc do lỗi từ dữ liệu thu thập (thông thường dữ liệu ngoại lệ dạng này sẽ bị loại khỏi tập dữ liệu). Một giá trị ngoại lệ có thể gây ra vấn đề nghiêm trọng trong quá trình phân tích dữ liệu.
–
Tài liệu tham khảo:Carin Viljoen, Linda van der Merwe. (2000). Elementary Statistics (2nd ed.). Pearson South Africa.Illowsky et al. (2013). Introductory Statistics. Houston: OpenStax.Wikipedia. (2021, March 24). Phương sai. Retrieved from Wikipedia: https://vi.wikipedia.org/wiki/Ph%C6%B0%C6%A1ng_sai
–
Các bài viết liên quan:
Thống kê mô tả trong nghiên cứu – Các đại lượng về trung tâm
Thống kê mô tả trong nghiên cứu – Các đại lượng về hình dáng phân phối
Thống kê mô tả trong nghiên cứu – Các đại lượng về sự tương quan
–
QUÝ ANH/CHỊ CẦN HỖ TRỢ XỬ LÝ, PHÂN TÍCH DỮ LIỆU VUI LÒNG GỬI THÔNG TIN QUA FORM DƯỚI ĐÂY
CHÚNG TÔI SẼ LIÊN HỆ VÀ PHÚC ĐÁP TRONG THỜI GIAN SỚM NHẤT
Đang tải…